Desenvolvimento de um aplicativo Web utilizando Python e Streamlit
Você quer saber como podemos criar um algoritmo de aprendizado de máquina e colocar ele disponível na sua empresa ou fora dela de uma maneira muito fácil e rápida, sem precisar configurar a AWS, Google Cloud ou Azure? Para isso vamos utilizar o Streamlit. Para saber o passo a passo para isso, basta continuar a leitura.
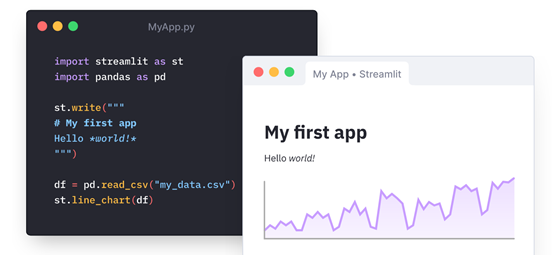
Hoje vamos executar um programa de machine learning (aprendizado de máquina)para verificar se a pessoa está propensa ter diabetes ou não, com base nas informações que ela vai inserir.
A nossa base de dados utilizada, é da Kaggle e se encontra disponível no seguinte link: https://www.kaggle.com/uciml/pima-indians-diabetes-database
Recomendo que antes de utilizá-la, você faça o tratamento dos dados, ok?
Vamos precisar também utilizar o Streamlit, mas o que ele é?
O Streamlit é um framework desenvolvido em Python que torna possível a criação de aplicativos elegantes para modelos de machine learning (aprendizagem de máquina) ou mesmo visualização de dados para uma simples análise exploratória de um dataset (conjunto de dados), além de possuir de forma nativa HTML e JavaScript, desta forma não é necessário saber programar nessas linguagens.
vai precisar estar realizando o download do Streamlit, através do link: https://streamlit.io/
Vamos utilizar também o PyCharm (IDE Python para desenvolvedores), link: https://www.jetbrains.com/pt-br/pycharm/download/#section=windows.
Vale lembrar que o seu ambiente Python deve estar já configurado para que possamos dar os primeiros passos na construção do nosso App.
Para começarmos precisamos instalar as bibliotecas que vamos utilizar. Para isso com o PyCharm aberto no seu terminal, basta inserir os seguintes comandos:
1) pip install streamlit
2) pip install scikit-learn
3) pip install matplotlib
4) pip install pandas
Se você não lembra o que essas bibliotecas significam, temos um artigo dedicado para a explicação delas, vale a pena conferir.
Agora que instalamos as bibliotecas que vamos utilizar, vamos fazer a importação delas.
Para isto para inserir o seguinte código:
#importando as bibliotecas
import pandas as pd
import streamlit as st
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
Explicando: Aqui estamos utilizando a biblioteca Pandas para trabalharmos com o conjunto de dados, a biblioteca Streamlit para a interface do nosso App, Sklearn para dividir o nosso conjunto de dados em treino e teste, utilizando para isso um classificador baseado em árvore de decisão, podendo no final verificar a acurácia do nosso modelo criado.
Vamos agora atribuir um título ao nosso aplicativo
#título
st.write(“Prevendo Diabetes”)
Realizando a leitura da base de dados:
#dataset
df = pd.read_csv(“C:/Users/Usuario/Desktop/dash/diabetes.csv”)
Criando um cabeçalho:
#cabeçalho
st.subheader(“Informações dos dados”)
Permitindo a inserção do nome do usuário pelo próprio.
#nomedousuário
user_input = st.sidebar.text_input(“Digite seu nome”)
Escrevendo o nome do usuário que foi dado na entrada:
#escrevendo o nome do usuário
st.write(“Paciente:”, user_input)
A partir daqui, vamos criar o nosso modelo, como dito anteriormente.
Vamos começar dividindo os nossos dados de entrada. Aqui o “x” recebe o “df.drop”, porque não queremos a coluna do campo “Outcome”, que é o campo com o resultado que diz se está ou não com diabetes, que é o que vamos estar treinando. Criamos depois a variável que precisamos para que apareça o resultado.
#dados de entrada
x = df.drop([‘Outcome’],1)
y = df[‘Outcome’]
Agora, vamos separar o conjunto de dados em treino e teste, utilizando 20% da base para teste e o restante para treinamento.
#separa dados em treinamento e teste
x_train, x_text, y_train, y_test = train_test_split(x, y, test_size=0.2)
Nesta etapa, vamos criar uma função para coletar os dados que irão ser inseridos pelos usuários. Como parâmetro, vamos definir um valor mínimo, um valor máximo e um valor default.
#dados dos usuários com a função
def get_user_date():
pregnancies = st.sidebar.slider(“Gravidez”,0, 15, 1)
glicose = st.sidebar.slider(“Glicose”, 0, 200, 110)
blood_pressure = st.sidebar.slider(“Pressão Sanguínea”, 0, 122, 72)
skin_thickness = st.sidebar.slider(“Espessura da pele”, 0, 99, 20)
insulin = st.sidebar.slider(“Insulina”, 0, 900, 30)
bni= st.sidebar.slider(“Índice de massa corporal”, 0.0, 70.0, 15.0)
dpf = st.sidebar.slider(“Histórico familiar de diabetes”, 0.0, 3.0, 0.0)
age = st.sidebar.slider (“Idade”, 15, 100, 21)
Criação de um dicionário para recebimento dessas informações.
#dicionário para receber informações
user_data = {‘Gravidez’: pregnancies,
‘Glicose’: glicose,
‘Pressão Sanguínea’: blood_pressure,
‘Espessura da pele’: skin_thickness,
‘Insulina’: insulin,
‘Índice de massa corporal’: bni,
‘Histórico familiar de diabetes’: dpf,
‘Idade’: age
}features = pd.DataFrame(user_data, index=[0])
return features
Agora estamos finalizando nosso aplicativo!!!
Vamos chamar a função criada e gerar um gráfico para exibir as informações.
O critério utilizado aqui foi a “entropia”, pois é usada para estimar a aleatoriedade da variável a prever (classe).
user_input_variables = get_user_date()
#grafico
graf = st.bar_chart(user_input_variables)
dtc = DecisionTreeClassifier(criterion=’entropy’, max_depth=3)
dtc.fit(x_train, y_train)
Aqui verificamos a acurácia do nosso modelo:
#acurácia do modelo
st.subheader(‘Acurácia do modelo’)
st.write(accuracy_score(y_test, dtc.predict(x_text))*100)
Vamos agora com o resultado da previsão, para verificar se o usuário tem ou não diabetes.
Se o resultado for igual a “0” ele não possui diabetes, caso seja igual a “1” ele possui diabetes.
#previsão do resultado
prediction = dtc.predict(user_input_variables)
st.subheader(‘Previsão:’)
st.write(prediction)
Agora vamos ver o resultado final?
Basta no seu terminal do PyCharm, inserir o comando para o Streamlit executar o seu script criado em Python, da seguinte forma: streamlit run “nome do seu script”

A seguir vamos visualizar o resultado:

Pronto, você possui o seu primeiro aplicativo!!!
Deixe o seu comentário, e me siga no LinkedIn para acompanhar mais informações.
Obrigada pela leitura, até a próxima!
Link do post original: https://medium.com/data-hackers/desenvolvimento-de-um-aplicativo-web-utilizando-python-e-streamlit-b929888456a5
LinkedIn da autora: https://www.linkedin.com/in/debora-gobbo-a63a3392/
- Categoria(s): ciencia de dados Débora Gobbo Linguagens de programação