Do scrap ao deploy com Shiny
Mostrando as empresas por trás dos tickers da bolsa e prevendo seu fechamento de maneira direta
A partir do momento que você precisa deixar uma análise, modelo ou mesmo um resultado disponível para as pessoas da sua equipe em qualquer momento, é hora de lidar com o que chamamos de deploy de produtos de dados.
O termo deploy remete a ação de automatizar aquilo que você fez na sua própria máquina, deixando o algoritmo executar periodicamente a rotina programada. Esse código pode ser de uma coleta, limpeza, modelagem, análise ou mesmo todas essas etapas juntas para compor um dashboard, como iremos fazer aqui hoje.
Assim, o problema que iremos resolver aqui é: mostrar de maneira dinâmica as principais características das empresa listadas na bolsa brasileira, a ibovespa, além de aplicar um modelo preditivo para tentar prever o fechamento de cada ticker nos dias seguintes ao acesso da dashboard, de modo que o usuário possa ter uma visão geral daquela empresa e tomar suas decisões de negócio baseada em dados.

Assim, pensando no ciclo acima e no problema exposto, seguiremos com os seguintes passos:
Coleta de dados
- Vamos entender como, quando e de onde coletaremos os dados. Dessa forma, a partir disso poderemos ver onde existe necessidade de adaptar a forma como usamos a fonte de dados para “plugar” da melhor maneira no nosso dashboard.
Desenvolvimento da aplicação
- Construir o painel em Shiny, pensando já que esse painel deverá “se manter sozinho”. Digo isso, pois se estamos acostumados a sempre construir uma análise para ser mantida localmente, criamos alguns hábitos como o uso de variáveis que armazenam os dados para uso linear durante o código, sofrendo mudanças que muitas vezes não podem ser desfeitas durante a compilação, como por exemplo, a limpeza de dados faltantes.
Deploy
- Por fim, chegamos ao ponto de publicar no Shiny Apps. Sempre tenha em mente algumas boas práticas nessa etapa, como: verificar se o arquivo do shiny está como app.R, se esse arquivo está em uma pasta própria para o projeto e se os possíveis arquivos utilizados estão dentro dessa pasta.
Coleta de dados
Pensando nos dados que alimentaram nosso painel, teremos duas fontes, sendo elas a API do Yahoo!, a Yahoo Finance, e um scrap da Wikipedia. A escolha dessas fontes têm motivos bem simples:
- A API do Yahoo é gratuita, tendo um limite de requests razoável para o nosso objetivo e a latência de atualização é viável, pensando que iremos querer somente fechamento dos tickers e não sua cotação em tempo real.
- A Wikipedia em sua natureza possui um bom padrão de publicação, de modo que uma rotina de webscraping consegue facilmente consumir seus dados.

Veja que o primeiro parágrafo de uma página de empresa conta com uma introdução simples e direta da mesma.
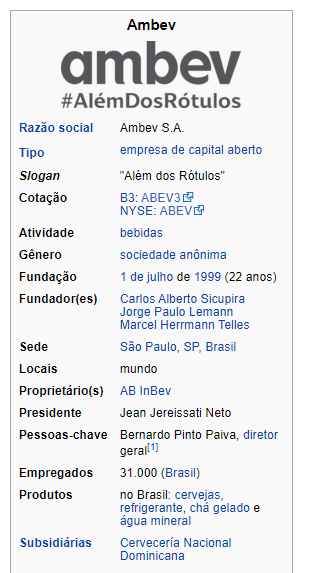
Além disso, o site disponibiliza um card que pode ser transformado em um “cartão de apresentação” da empresa em forma de tabela.

Por fim, a própria Wikipedia disponibiliza também uma tabela com as principais empresas listadas na bolsa de valores, implantando em cada um dos nomes o link que guia para sua página na enciclopédia digital, de modo que possamos usar essa lista para construir a escolha do usuário de qual empresa ele gostaria de ver em sua tela, guiando qual “vertente” da Wikipedia devemos puxar os dados.
Desenvolvimento e deploy da aplicação
Dado que o Shiny possui um server gratuito disponível para deploy, isto é, podemos deixar nosso painel disponível para quem queira acessar (podendo até implementar uma página de autenticação, se necessário), iremos programar o dashboard em R e publicar no shinyapps.io.
É legal ressaltar que além do shinyapps, outra alternativa muito interessante para quem programa em python e deseja colocar seus dashboards em produção é o Streamlit , pelo qual podemos vincular um código no github para virar um painel.
Agora que já sabemos de todos os passos a serem seguidos, é hora de por a mão na massa!
library(tidyr)
library(dplyr)
library(rvest)
library(dygraphs)
library(BatchGetSymbols)
library(shiny)
library(forecast)# tabela de acoes
wiki1 <- "https://pt.wikipedia.org/wiki/Lista_de_companhias_citadas_no_Ibovespa"
doc1 <- read_html(wiki1)
doc1 %>%
html_nodes(xpath = '//*[@id="mw-content-text"]/div/table[1]') %>%
html_table() -> tabela_b3
tabela_acoes <- as.data.frame(tabela_b3)
Importando as bibliotecas que serão utilizadas, podemos ver alguns nomes comuns para os mais familiarizados com R, como tidyr, dplyr, rvest e shiny. Quanto as outras bibliotecas, temos a seguinte composição:
- Dygraphs: biblioteca que entrega gráficos interativos de “candle”, famosos no mundo da renda variável.
- BatchGetSymbols: API do Yahoo! Finance
- Forecast: algoritmos de manipulação e modelagem de séries temporais
Dito isso, começamos com o scrap de dados da Wikipedia, e para esse tarefa iremos iniciar com a coleta dos dados da tabela de tickers. Nesse momento, a ideia é que apontemos a página, por meio de uma URL, a qual iremos escolher o componente HTML que queremos coletar, e por fim, passamos o dado coletado para um dataframe.
links = doc1 %>% html_nodes(xpath = "//td/a") %>%
html_attr("href")
links = data.frame(links)
links = links %>% filter(!grepl("/wiki/Ficheiro",links) & !grepl("http://www.taesa.com.br/",links))
Visto que sabemos que os links para cada empresa estão como hiperlinks, passamos novamente um “filtro” no HTML, pegando esses dados e retirando alguns erros de processamento, como duplicação ou termos que não gostaríamos que aparecesse no dataframe de links.
tabela_acoes = tabela_acoes %>% filter(`Código` != "BBDC3" & `Código` !="PETR3" & `Código` !="BRML3" & `Código` != "CCRO3" & `Código` != "ELET3")
acesso = cbind(tabela_acoes,links)
acesso = acesso %>% select(`Código`,links)
Por fim, retiramos alguns casos onde a tabela está mesclada, de modo que o join entre os links de cada empresa no Wikipedia e o ticker permaneçam na mesma ordem. Unimos os dados em um único dataframe e fechamos a etapa de coleta.
ui <- fluidPage(
theme = shinythemes::shinytheme("united"),titlePanel("Conhecendo a B3"),sidebarLayout(
sidebarPanel(
h3("Escolha uma ação"),
selectInput("escolha_acao", "Ação:",
choices = acesso$Código)
),
mainPanel(
textOutput("nome_empresa"),
tags$hr(style="border-color: white;"),tags$hr(style="border-color: white;"),
textOutput("primeiro_paragrafo"),
tags$hr(style="border-color: white;"),tags$hr(style="border-color: white;"),
DT::dataTableOutput("card_wiki"),
tags$hr(style="border-color: white;"),tags$hr(style="border-color: white;"),
h3("Cotação Histórica da empresa"),
dygraphOutput("candle"),
tags$hr(style="border-color: white;"),tags$hr(style="border-color: white;"),
h3("Previsão para os próximos dias (fechamento)"),
tags$hr(style="border-color: white;"),
DT::dataTableOutput("prev"),
)
)
)
Partindo para a construção da interface, codificamos um painel simples de seleção do ticker com SidebarPanel, alinhado a dois componentes de texto dinâmicos (título e primeiro parágrafo), uma tabela dinâmica, um gráfico candle e uma outra tabela para soltar a previsão do ticker.
server <- function(input, output) {
output$card_wiki = DT::renderDataTable({
acesso = acesso %>% filter(`Código`== input$escolha_acao)
wiki1 <- paste0("https://pt.wikipedia.org/",acesso$links[1])
doc1 <- read_html(wiki1)
doc1 %>%
html_nodes(xpath = '//*[@id="mw-content-text"]/div/table[1]') %>%
html_table() -> tabela_carac_acao
tabela_carac_acao <- as.data.frame(tabela_carac_acao)
tabela_carac_acao <- tabela_carac_acao[-1,]
DT::datatable(
tabela_carac_acao , options = list(paging = FALSE,searching = FALSE))
})
output$primeiro_paragrafo <- renderText({acesso = acesso %>% filter(`Código`== input$escolha_acao)
wiki2 <- paste0("https://pt.wikipedia.org/",acesso$links[1])
doc2 <- read_html(wiki2)
doc2 %>%
html_nodes(xpath = '//*[@id="mw-content-text"]/div/p[1]') %>%
html_text() -> primeiro_par
primeiro_par
})
output$nome_empresa <- renderText({
acesso = acesso %>% filter(`Código`== input$escolha_acao)
wiki2 <- paste0("https://pt.wikipedia.org/",acesso$links[1])
doc2 <- read_html(wiki2)
doc2 %>%
html_nodes(xpath = '//*[@id="firstHeading"]') %>%
html_text() -> nome_empresa
nome_empresa
})
output$candle <- renderDygraph({
acesso = acesso %>% filter(`Código`== input$escolha_acao)
inicio <- "2018-01-01"
final <- Sys.Date()
bench.ticker <- "^BVSP"
saida <- BatchGetSymbols(tickers = paste0(acesso$Código,".SA"), first.date = inicio, last.date = final,
bench.ticker = bench.ticker)
saida <- as.data.frame(saida$df.tickers)
row.names(saida) <- saida$ref.date
m <- saida %>% dplyr::select(-ref.date,-price.adjusted,-volume,-ticker,-ret.adjusted.prices,-ret.closing.prices)
colnames(m) <- c("Open","High","Low","Close")
dygraph(m) %>%
dyCandlestick()
})
output$prev = DT::renderDataTable({
acesso = acesso %>% filter(`Código`== input$escolha_acao)
inicio <- "2018-01-01"
final <- Sys.Date()
bench.ticker <- "^BVSP"
saida <- BatchGetSymbols(tickers = paste0(acesso$Código,".SA"), first.date = inicio, last.date = final,
bench.ticker = bench.ticker)
saida <- as.data.frame(saida$df.tickers)
row.names(saida) <- saida$ref.date
d <- saida %>% dplyr::select(-ref.date,-price.adjusted,-volume,-ticker,-ret.adjusted.prices,-ret.closing.prices)
colnames(d) <- c("Open","High","Low","Close")
tabela = as.data.frame(forecast(nnetar(ts(d$Close,start = c(2018), frequency = 365)),h=4))
tabela = format(round(tabela, 2))
rownames(tabela) <- c(Sys.Date()+1,Sys.Date()+2,Sys.Date()+3,Sys.Date()+4)
DT::datatable(tabela, options = list(paging = FALSE,searching = FALSE))
})}
Passando para a codificação do “backend”, iniciamos a construção do server. O nome da empresa, primeiro parágrafo e tabela da Wikipedia são configurados para terem a dinâmica de usar o que o usuário escolheu, juntando com o link da Wikipedia e fazendo uma varredura na página da empresa.
Para o gráfico candle e a previsão, usamos a escolha do usuário para fazer um request na API do Yahoo! em dados de 2018 em diante, de modo que seja possível plotar e realizar uma previsão através de uma Rede Neural Feed-forward para os próximos 4 dias.
Concluindo nosso trabalho, é só publicar no Shinyapps!
O resultado pode ser visto em https://matheusduzzi.shinyapps.io/wiki/
- Categoria(s): ciencia de dados Matheus Duzzi Ribeiro Professores colaboradores