REGRESSÃO LOGÍSTICA EM: A MENOR DEEP LEARNING DO MUNDO
Este artigo foi postado originalmente no https://www.curso-r.com/blog/
OBJETIVOS
A finalidade do post é:
- aprender a fazer uma regressão logística com o keras
- aprender a fazer um PCA com o keras
- aproximar o Deep Learning do que já havia de conhecido pela maioria dos analistas de dados.
- instigar a todos que vieram antes do deep learning a estudar e a ficar à vontade com as novidades em torno dela.
- mostrar que muitos profissionais inseridos na área de machine learning já conheciam grande parte do que o deep learning usa.
- levantar discussão sobre alguns mitos que não são construtivos para a comunidade dos analistas de dados.
MOTIVAÇÃO
Li estatísticos, cientistas da computação, engenheiros de dados a afins questionando o futuro do Machine Learning e se tudo que conhecíamos antes sobre modelagem estatística havia ficado obsoleto (como essa pergunta no Quora: Should I Quit Machine Learning?).
E em conversas com pessoas próximas percebia certa ufania pela novidade e frustração pela “obsolência” do que se havia investido tempo estudando antes.
Para piorar, aproveitadores pegaram jacaré nessa onda para fazer marketing malicioso com o intuito de desvalorizar e dividir a comunidade dos analistas de dados. Algo bem similar com o que aconteceu com outras palavras da moda como data science, big data, Python versus R e a própria machine learning. Antes havia a clássica propaganda de que a empresa X utilizava MACHINE LEARNING em vez de modelos preditivos. Agora a coisa evoluiu e apelam para o uso da palavra Deep Learning.
O que realmente importa:
- Deep Learning é uma grande novidade e colocou a Inteligência Artificial em evidência.
- Quem manjava Machine Learning antes vai conseguir aplicar 95% do seu conhecimento nas aplicações de Deep Learning (incluindo baysianismo, bootstrap, inferência, probabilidade e a boiada toda).
- Deep Learning tem que ser visto como uma ferramenta a mais na caixa do analista de dados e não um substituto.
E para abordar essa questão resolvi ajustar uma regressão logística usando deep learning para que todos que já fizeram uma regressão logística antes possam dizer que já fizeram uma rede neural também! Confesso ter uma leve motivação provocativa, mas qual graça teria se assim não fosse? =P
O QUE FAREMOS
- Regressão logística para Y1Y1 (com
glm) - Deep Learning para Y1Y1 (com
keras) - Mostrar que regressão logística não é o melhor para Y2Y2 e que Deep Learning vai além da limitação dos modelos lineares (com
glm) - Deep Learning para Y2Y2 (com
keras)
Mãos à obra.
PACOTES
library(keras)
library(dplyr)
library(tidyr)
library(forcats)
library(ggplot2)REGRESSÃO LOGÍSTICA VERSUS DEEP LEARNING
Hora de ajustar modelos para os mesmos dados de duas maneiras diferentes: regressão logística com glm e deep learning com o keras.
DADOS SIMULADOS
logit <- function(p) log(p) - log(1 - p)
logistic <- function(x) 1/(1 + exp(-x))
n <- 100000
set.seed(19880923)
df <- data_frame(x = runif(n, -2, 2.5)) %>%
mutate(y_1 = rbinom(n, 1, prob = logistic(-1 + 2 * x)), # y_1
y_2 = rbinom(n, 1, prob = logistic(-1 + 2 * tanh(-1 + 2 * x)))) # y_2O código acima criou duas variáveis respostas (targets). Em representação matemática, elas possuem as seguintes definições:
Resposta y_1
E[Y1|x]=logistic(−1+2x)=11+e−(−1+2x)E[Y1|x]=logistic(−1+2x)=11+e−(−1+2x)
Resposta y_2
E[Y2|x]=logistic(−1+2tanh(−1+2x))=11+e−(−1+2tanh(−1+2x))E[Y2|x]=logistic(−1+2tanh(−1+2x))=11+e−(−1+2tanh(−1+2x))
xx é linear no logito de y_1, então a regressão logística vai cair bem para descobrir os parâmetros −1−1 e 22. Porém, xx não é linhar no logito de y_2 e por isso a regressão logística não conseguirá representar fielmente o gerador de y_2.
OBS 1: A forma logistic(β0+β1tanh(β2+β3X))logistic(β0+β1tanh(β2+β3X)) tem parâmetros dentro do função tanh, o que significa que a nossa hipótese para E[Y2|x]E[Y2|x] não é mais linear nos parâmetros. Por isso que modelos lineares (como o nome sugere) não são mais indicados. E a não linearidade é uma das generalizações que as redes neurais nos fornece! (sim, isso é muito relevante)
OBS 2: é claro que nesse caso bem simples de uma variável conseguiríamos inspecionar os dados para chegar em boas transformações de xx de tal forma que o ajuste da logística ficasse tão bom quanto o de uma rede neural, mas se acrescentássemos muitas outras variáveis aí a coisa complicaria!
Em representação de redes neurais, as fórmulas acima ficam assim:
Resposta y_1
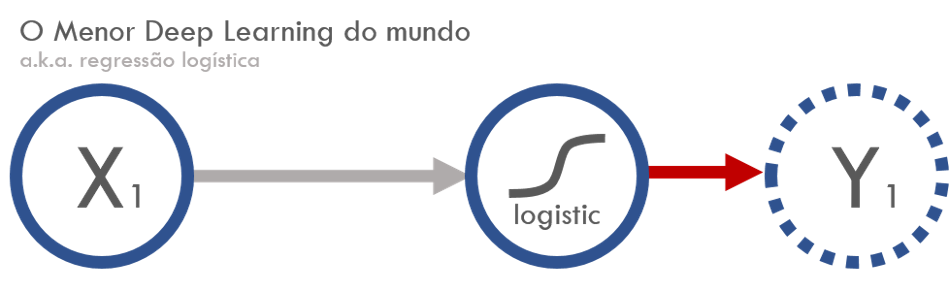
Resposta y_2
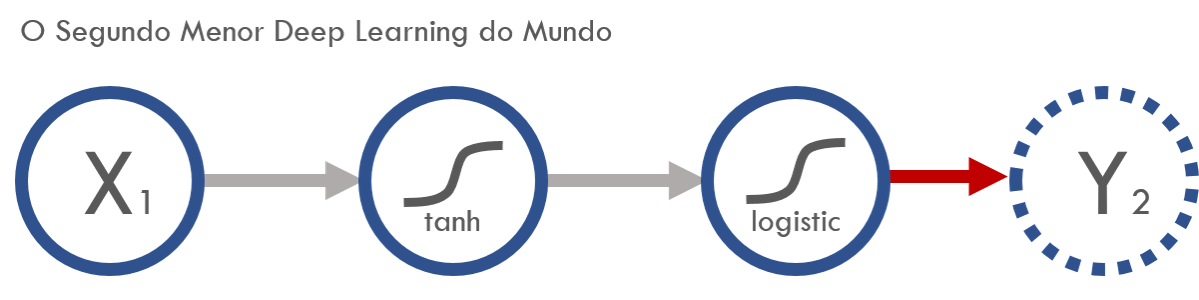
O que era função de ligação no GLM, em redes neurais virou função de ativação (no final eu falo mais sobre vocabulários que mudaram).
OLHADA NOS DADOS
# skimr::skim(df) %>% skim_print %>% with(numeric) %>% mutate_if(is.numeric, round, 2) %>% DT::datatable()
df %>%
gather(y_id, y_val, y_1, y_2) %>%
mutate(x_cat = cut_number(x, n = 70)) %>%
group_by(x_cat, y_id) %>%
summarise(p = mean(y_val),
n = n()) %>%
mutate(logit_p = logit(p)) %>%
gather(transformacao, p, p, logit_p) %>%
mutate(transformacao = transformacao %>% fct_inorder %>% fct_recode("logit(p)" = "logit_p")) %>%
ggplot() +
geom_point(aes(x = x_cat, y = p, colour = y_id)) +
theme_minimal(20) +
theme(axis.text.x = element_text(angle = 90, hjust = 1, vjust = 0.5)) +
facet_wrap(~forcats::fct_inorder(transformacao), nrow = 1, scales = "free_y") +
labs(x = "x", colour = "resposta") +
theme(axis.text.x = element_blank(),panel.grid.major.x = element_blank(), panel.grid.minor.y = element_blank())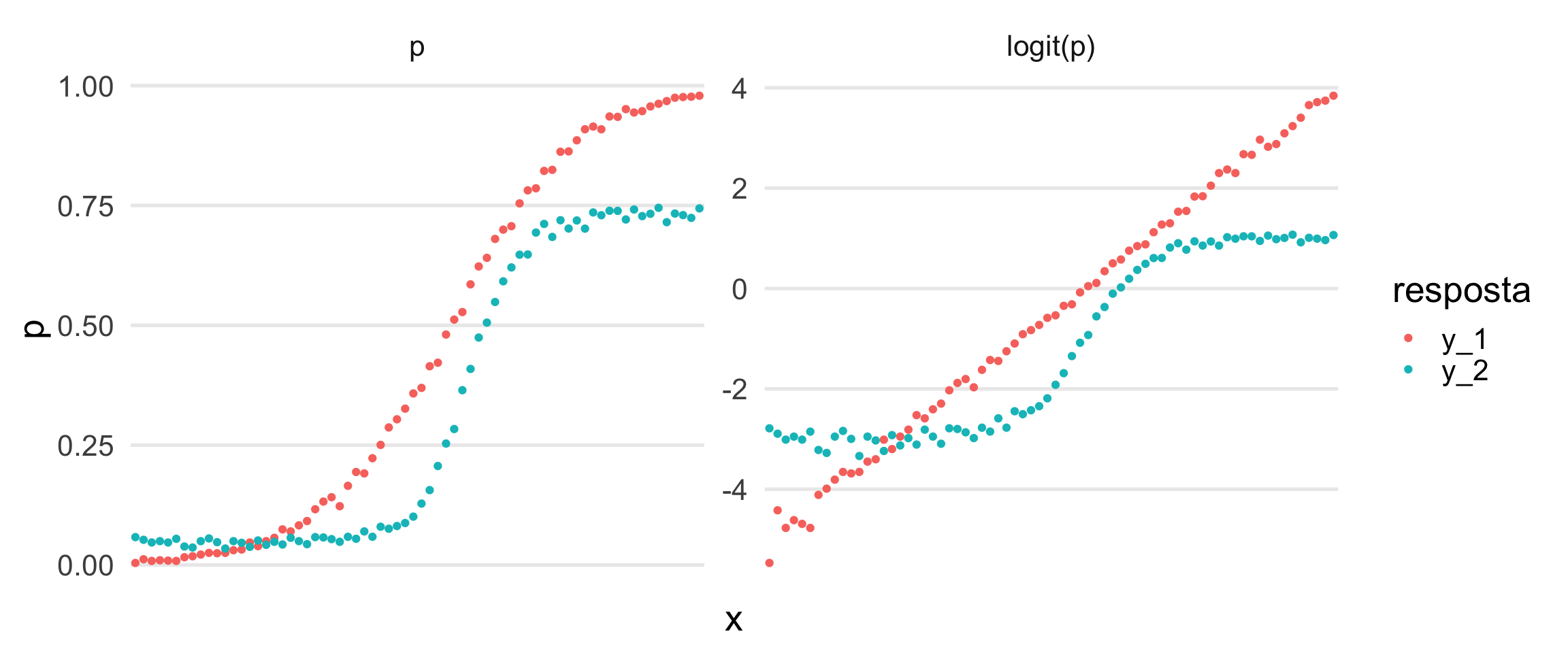
O gráfico da direita mostra que x é proporcional ao logito das probabilidades de y_1 (em vermelho) como era pra ser por termos construído assim. Já com o y_2 (em azul) ainda ficou parecendo uma sigmoide mesmo depois da transformação.
AJUSTE DE MODELOS
REGRESSÃO LOGÍSTICA PARA Y1Y1 (COM GLM)
# modelo glm 1 ------------------------------------------------------
modelo_glm_1 <- glm(y_1 ~ x, data = df, family = binomial)# coefficients
coef(modelo_glm_1)
# (Intercept) x
# -1.018434 2.011647
# accuracy
conf_matrix_glm_1 <- table(modelo_glm_1$fitted.values > 0.5, df$y_1)
sum(diag(conf_matrix_glm_1))/sum(conf_matrix_glm_1)
# [1] 0.85061As estimativas ficaram bem próximas dos verdadeiros valores β0=−1β0=−1 e β1=2β1=2.
A acurácia foi de 85%.
DEEP LEARNING PARA Y1Y1 (COM KERAS)
Vamos montar nossa hipótese para E[Y1|x]E[Y1|x].
# modelo keras 1 -------------------------------------------------------
# input: 1 variável: o x.
input_keras_1 <- layer_input(1, name = "modelo_keras_1")
# output: não há camadas escondidas, apenas a função de ligação logit diretamente.
output_keras_1 <- input_keras_1 %>%
layer_dense(units = 1, name = "camada_unica") %>%
layer_activation("sigmoid", input_shape = 1, name = "link_logistic") # sigmoid no tensorflow é a logistic
# keras_model é o que constrói a nossa hipótese f(x) (da E[y] = f(x))
modelo_keras_1 <- keras_model(input_keras_1, output_keras_1)
#
summary(modelo_keras_1)Model
_____________________________________________________________
Layer (type) Output Shape Param #
=============================================================
modelo_keras_1 (InputLayer) (None, 1) 0
_____________________________________________________________
camada_unica (Dense) (None, 1) 2
_____________________________________________________________
link_logistic (Activation) (None, 1) 0
=============================================================
Total params: 2
Trainable params: 2
Non-trainable params: 0
_____________________________________________________________A hipótese construída tem 2 parâmetros. Parece que está certo! β0β0 e β1β1.
Agora é a vez da função de perda.
Como nosso objetivo é construir uma regressão logística, nós vamos escolher a função de perda binary_crossentropy que é sinônimo de deviance da logística, termo mais comum no mundo da estatística.
A métrica 'accuracy' não entra no otimizador da função de perda, a gente usa ela para comparar os modelos que criamos. No caso vamos comparar com o modelo glm ajustado acima (mas, por exemplo, em caso de eventos raros a 'accuracy' não vai ser muito informativa, daí poderíamos usar 'auc', 'gini', etc.).
modelo_keras_1 %>% compile(
loss = 'binary_crossentropy',
optimizer = optimizer_sgd(lr = 0.4),
metrics = c('accuracy')
)
modelo_keras_1_fit <- modelo_keras_1 %>% fit(
x = df$x,
y = df$y_1,
epochs = 20,
batch_size = 1000,
verbose = 0
)# coefficients
modelo_keras_1 %>% get_layer("camada_unica") %>% get_weights
# [[1]]
# [,1]
# [1,] 2.000054
#
# [[2]]
# [1] -1.015561
# accuracy
loss_and_metrics_1 <- modelo_keras_1 %>% evaluate(df$x, df$y_1, batch = 100000, verbose = 0)
loss_and_metrics_1[[2]]
# [1] 0.85053Resultados idênticos! Era para assim ser porque construímos a mesma hipótese e a memsa função de perda do glm.
REGRESSÃO LOGÍSTICA PARA Y2Y2 (COM GLM)
Para modelar Y2Y2 vamos pisar em terrenos que os modelos lineares não pisam. Primeiro tento ajustar uma curva uasndo x e a transformação tanh(x). Esse preditor eu suponho que escolhi depois de uma minuciosa e demorada inspeção dos dados (tentei simular mais ou menos o que eu faria numa modelagem onde eu que teria que construir as features na mão).
# modelo glm 2 ------------------------------------------------------
modelo_glm_2 <- glm(y_2 ~ x + tanh(x), data = df, family = binomial)
# coefficients
coef(modelo_glm_2)
# (Intercept) x tanh(x)
# -1.6698641 0.3043212 2.0936353
# accuracy
conf_matrix_glm_2 <- table(modelo_glm_2$fitted.values > 0.5, df$y_2)
sum(diag(conf_matrix_glm_2))/sum(conf_matrix_glm_2)
# [1] 0.82204Acurácia de 82%, nada mal. Mas a hipótese e parâmetros foram distintos do verdadeiro gerador dos dados. Vamos usar redes neurais para resolver o problema de não linearidade.
DEEP LEARNING PARA Y2Y2 (COM KERAS)
Hipótese para E[Y2|x]E[Y2|x].
# modelo keras 2 -------------------------------------------------------
input_keras_2 <- layer_input(1, name = "modelo_keras_2")
output_keras_2 <- input_keras_2 %>%
layer_dense(units = 1, name = "camada_um") %>%
layer_activation("tanh", input_shape = 1, name = "tanh_de_dentro") %>%
layer_dense(units = 1, input_shape = 1, name = "camada_dois") %>%
layer_activation("sigmoid", input_shape = 1, name = "link_logistic")
modelo_keras_2 <- keras_model(input_keras_2, output_keras_2)
summary(modelo_keras_2)Model
_____________________________________________________________
Layer (type) Output Shape Param #
=============================================================
modelo_keras_2 (InputLayer) (None, 1) 0
_____________________________________________________________
camada_um (Dense) (None, 1) 2
_____________________________________________________________
tanh_de_dentro (Activation) (None, 1) 0
_____________________________________________________________
camada_dois (Dense) (None, 1) 2
_____________________________________________________________
link_logistic (Activation) (None, 1) 0
=============================================================
Total params: 4.0
Trainable params: 4.0
Non-trainable params: 0.0
_____________________________________________________________
Quatro parâmetros ‘treináveis’, é isso aí! Dois parâmetros de dentro do tanh e os dois parâmetros de fora. Precisamos que o keras nos devolva -1, 2, -1 e 2 do jeito que geramos os dados.
Função de custo
modelo_keras_2 %>% compile(
loss = 'binary_crossentropy',
optimizer = optimizer_sgd(lr = 0.1),
metrics = c('accuracy')
)
modelo_keras_2_fit <- modelo_keras_2 %>% fit(
x = df$x,
y = df$y_2,
epochs = 20,
batch_size = 100,
verbose = 0
)
# coefficients
modelo_keras_2 %>% get_layer("camada_um") %>% get_weights
# [[1]]
# [,1]
# [1,] 2.012015
#
# [[2]]
# [1] -1.058052
modelo_keras_2 %>% get_layer("camada_dois") %>% get_weights
# [[1]]
# [,1]
# [1,] 1.981977
#
# [[2]]
# [1] -1.006567
# accuracy
loss_and_metrics_2 <- modelo_keras_2 %>% evaluate(df$x, df$y_2, batch_size = 100000)
loss_and_metrics_2[[2]]
# [1] 0.82221Precisão de 82% também, mas agora os parâmetros estão bem próximos daqueles que geraram os dados! Acabamos de ver um conjunto de parâmetros sendo encontrados mesmo com relação não linear entre eles e a média.
A precisão entre os dois modelos até que se equiparou, mas o gráfico das hipóteses encontradas (abaixo) mostra que a curva do glm está pior do que a curva do keras.
df %>%
select(x, y_2) %>%
mutate(x_cat = cut_number(x, n = 50)) %>%
group_by(x_cat) %>%
summarise(p = mean(y_2),
x = mean(x),
keras = logistic(-1.006567 + 1.981977 * tanh(-1.058052 + 2.012015 * x)),
glm = logistic(-1.6698641 + 0.3043212*x + 2.0936353 * tanh(x)),
n = n()) %>%
mutate(logit_p = logit(p)) %>%
gather(Modelo, estimativa, keras, glm) %>%
ggplot() +
geom_point(aes(x = x_cat, y = p)) +
geom_line(aes(x = x_cat, y = estimativa, colour = Modelo, group = Modelo)) +
theme_minimal() +
theme(axis.text.x = element_text(angle = 90, hjust = 1, vjust = 0.5)) +
labs(x = "x", colour = "resposta")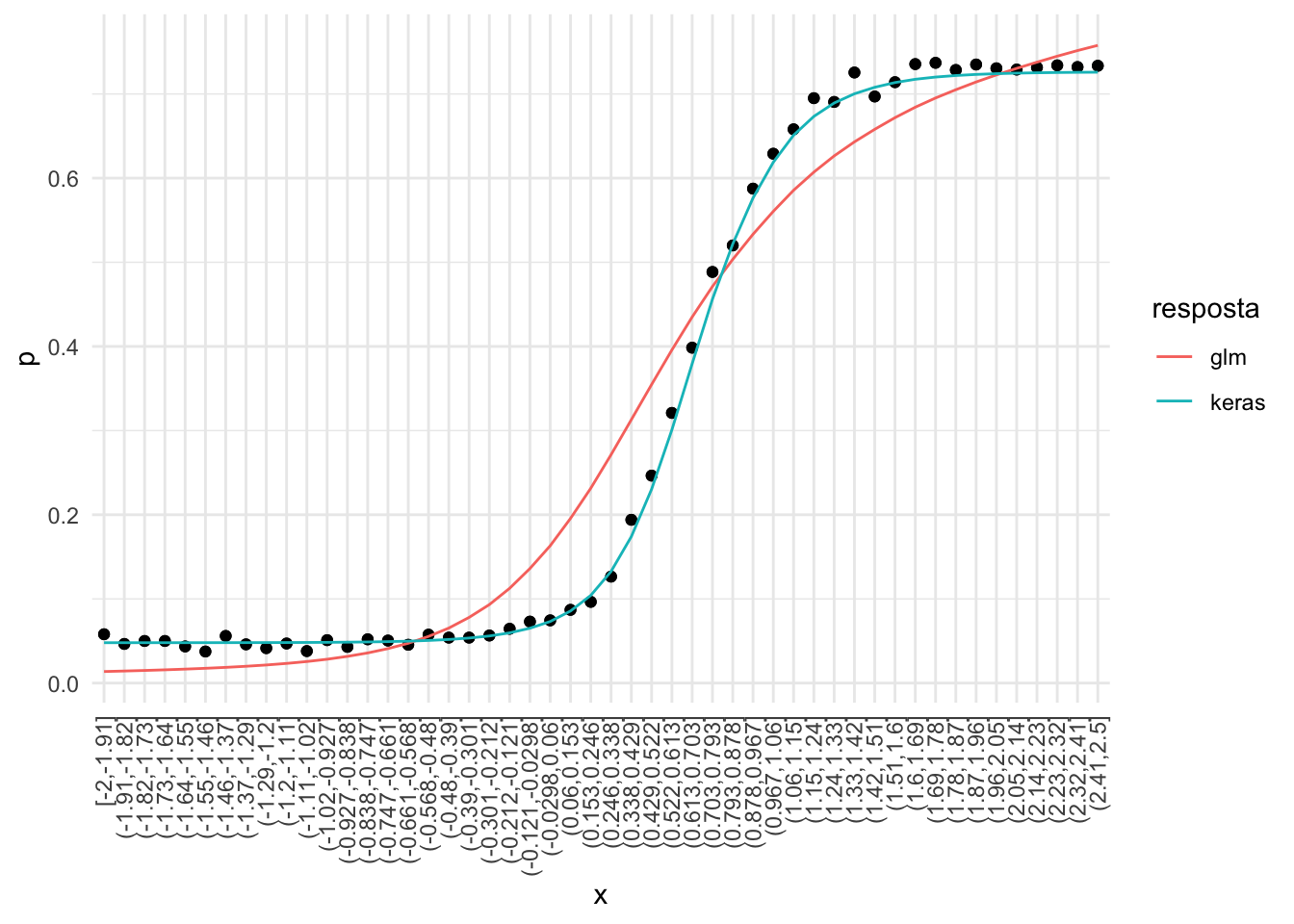
(BÔNUS) PCA COM AUTOENCOER
PCA e autoencodes servem na prática para reduzir a dimensionalidade dos dados. PCA é um caso particular de autoencoder com apenas uma camada e funções de ativação lineares. O post Construindo Autoencoders ensina a fazer e recomendo a leitura.
Resumo: autoencoder é uma técnica incrível que generaliza o PCA.
DISCUSSÃO
Na minha opinião aconteceu de que muita coisa antiga e consagrada teve seu nome mudado e apresentado como novo e isso acabou ofuscando as grandes contribuições realmente relevantes das pesquisas em torno das redes neurais e do deep learning.
Percebe-se que o Deep Learning generalizou bastante coisa e por isso eu declaro o post bem sucedido se o escrito acima despertou curiosidade em aprender mais sobre deep learning para agregar ao trabalho que já havia sendo feito. Vale mais a pena trazer todos os praticantes de estatística e machine learning juntos nessa novidade do que nos dividirmos.
Acredito que mais do que nunca a fundamentação teórica e interpretações terão seu valor potencializado com a disseminação do deep learning. Com o mito de que deep learning seja uma panaceia e com a facilidade que ela nos trouxe para fazer um modelo preditivo, há o risco de sermos soterrados por caixas pretas feitas por pessoas negligentes com aspectos importantes como interpretabilidade, causalidade e generalização. Talvez o bayesianismo se desponte (mais uma vez) como a solução para problemas qualitativos num mundo cada vez mais obscuro trazendo à luz os excessos dos modelos complexos e os benefícios dos modelos simples.
Puxando o gancho do bayesianismo (e inferências em geral), os resultados já obtidos em cima de modelos lineares ainda se aplicam em deep learning. E também temos a vantagem de que todas as demais ferramentas que se usam em deep learning e que não afetam a linearidade dos parâmetros podem ser utilizadas, como convolucional, recorrente, max pooling, drop out, autoencoder e tantas outras.
Para finalizar, na prática sugiro aplicar deep learning com o Keras, um pacote incrível que usa o tensorflow ou o theano por trás. Acredito que vocês verão muitos posts sobre o assunto por aqui! (podem encher o saco do Dan Falbel, um dos sócios da curso-r.com, que está envolvido no desenvolvimento desse pacote em R =]).
CURIOSIDADES
N-ÉSIMO MENOR DEEP LEARNING
Vimos acima o menor e o segundo menor Deep Learnings (que de profundo não têm nada =P). Mas podemos ir o tão profundo quanto quisermos! A representação de redes neurais sai fácil:

Já a representação matemática fica esquisita:
E[Y|x]=11+exp⎛⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜⎝βp−1+βp1⋮1+exp⎛⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜⎝β6+β711+exp⎛⎜ ⎜ ⎜ ⎜ ⎜ ⎜⎝β4+β511+exp(β2+β311+exp(β0+β1x))⎞⎟ ⎟ ⎟ ⎟ ⎟ ⎟⎠⎞⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟⎠⎞⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟⎠E[Y|x]=11+exp(βp−1+βp1⋮1+exp(β6+β711+exp(β4+β511+exp(β2+β311+exp(β0+β1x)))))
VOCABULÁRIO
Os jargões e termos do deep learning foram herdados de um outro contexto diferente do da modelagem preditiva estudada na estatística e por isso acabaram surgindo inúmeros sinônimos. Alguns deles são:
- função de ativação = função de ligação
- Softmax = verossimilhança da multinomial
- sigmoide = função com formato de S (no tensorflow o padrão é a logistic)
- pesos = parâmetros/betas/coeficientes
- binary crossentropy = deviance da distribuição binomial (regressão logística)
É isso aí, temos que nos manter curiosos, questionar e dialogar. Abs!
Linkedin do professor: https://www.linkedin.com/in/athosdamiani/
#regressaologistica #deeplearning #redesneurais
- Categoria(s): Athos Damiani ciencia de dados