Utilizando o R para obter decretos relacionados ao COVID-19 no Brasil
Introdução
No Brasil, diante da emergência sanitária mundial, as autoridades estabeleceram diversas portarias/decretos com regras e normas para funcionamento de serviços de saúde e serviços não essenciais.
Na maioria das unidades da federação, as aulas na rede pública e na rede privada foram suspensas. Eventos com grande número de pessoas foram proibidos. Houve mudanças no transporte público, com redução de frota, e alterações nas regras de abertura de comércios, bares, restaurantes e shoppings.
O objetivo dessas restrições era de evitar a sobrecarga dos serviços de saúde e esgotamento dos leitos de tratamento, à medida que, a União, Estados e Municípios poderiam se preparar para o aumento no número de casos com a construção de hospitais de campanha e importação de respiradores.
Ao longo dos últimos meses os decretos vêm sendo moldados de acordo com a realidade da pandemia no país. Mudanças como aumento das restrições de circulação e expansão na oferta de crédito, foram mais recentemente transformadas em medidas de reabertura de algumas atividades econômicas com estruturas e horários de funcionamento diferenciados, entre outros tipos. Uma forma de olhar o panorama do Covid-19 no país é observando como os agentes políticos legislaram a respeito do tema.
No texto a seguir explico como gerar um banco de dados no R com informações atualizadas sobre os decretos nos níveis municipal, estadual e federal, com registro da data, sua classificação em decreto ou lei e algumas outras informações.
Vamos lá!
Carregando os dados e os pacotes no R
A fonte dos dados vem do site https://leismunicipais.com.br/, que é totalmente confiável, tanto que vários municípios utilizam a ferramenta. Você pode encontrar mais informações sobre eles aqui.
O ‘Leis Municipais’ vem mantendo uma página com dados sobre os decretos relacionados ao Covid-19, é dessa página que vamos extrair as informações, de dentro do R, é claro.
# Pacotes
library(dplyr)
library(tidyr)
library(purrr)
library(xml2)
library(stringr)
library(rvest)
library(mgsub)
library(gsubfn)
library(lubridate)# Pasta de trabalho - altere o caminho para onde os arquivos serão salvos #
setwd("C:\\Users\\pc\\Desktop\\Cidacs\\ETL")########################################################
#### DECRETOS POR ESTADO
########################################################Acre <- read.csv2("https://leismunicipais.com.br/coronavirus?estado=AC", encoding = 'UTF-8', sep=",", stringsAsFactors = F) %>% mutate(Estado = "Acre")Alagoas <- read.csv2("https://leismunicipais.com.br/coronavirus?estado=AL", encoding = 'UTF-8', sep=",", stringsAsFactors = F) %>% mutate(Estado = "Alagoas")Amapá <- read.csv2("https://leismunicipais.com.br/coronavirus?estado=AP", encoding = 'UTF-8', sep=",", stringsAsFactors = F) %>% mutate(Estado = "Amapá")Amazonas <- read.csv2("https://leismunicipais.com.br/coronavirus?estado=AM", encoding = 'UTF-8', sep=",", stringsAsFactors = F) %>% mutate(Estado = "Amazonas")Bahia<- read.csv2("https://leismunicipais.com.br/coronavirus?estado=BA", encoding = 'UTF-8', sep=",", stringsAsFactors = F) %>% mutate(Estado = "Bahia")Ceará <-read.csv2("https://leismunicipais.com.br/coronavirus?estado=CE", encoding = 'UTF-8', sep=",", stringsAsFactors = F) %>% mutate(Estado = "Ceará")Distrito_Federal<- read.csv2("https://leismunicipais.com.br/coronavirus?estado=DF", encoding = 'UTF-8', sep=",", stringsAsFactors = F) %>% mutate(Estado = "Distrito Federal")Espírito_Santo <-read.csv2("https://leismunicipais.com.br/coronavirus?estado=ES", encoding = 'UTF-8', sep=",", stringsAsFactors = F) %>% mutate(Estado = "Espírito Santo")Goiás <- read.csv2("https://leismunicipais.com.br/coronavirus?estado=GO", encoding = 'UTF-8', sep=",", stringsAsFactors = F) %>% mutate(Estado = "Goiás")Maranhão <- read.csv2("https://leismunicipais.com.br/coronavirus?estado=MA", encoding = 'UTF-8', sep=",", stringsAsFactors = F) %>% mutate(Estado = "Maranhão")Mato_Grosso <- read.csv2("https://leismunicipais.com.br/coronavirus?estado=MT", encoding = 'UTF-8', sep=",", stringsAsFactors = F) %>% mutate(Estado = "Mato Grosso")Mato_Grosso_do_Sul <-read.csv2("https://leismunicipais.com.br/coronavirus?estado=MS", encoding = 'UTF-8', sep=",", stringsAsFactors = F) %>% mutate(Estado = "Mato Grosso do Sul")Minas_Gerais <- read.csv2
("https://leismunicipais.com.br/coronavirus?estado=MG", encoding = 'UTF-8', sep=",", stringsAsFactors = F) %>% mutate(Estado = "Minas Gerais")Pará <- read.csv2("https://leismunicipais.com.br/coronavirus?estado=PA", encoding = 'UTF-8', sep=",", stringsAsFactors = F) %>% mutate(Estado = "Pará")Paraíba <- read.csv2("https://leismunicipais.com.br/coronavirus?estado=PB", encoding = 'UTF-8', sep=",", stringsAsFactors = F) %>% mutate(Estado = "Paraíba")Paraná <- read.csv2("https://leismunicipais.com.br/coronavirus?estado=PR", encoding = 'UTF-8', sep=",", stringsAsFactors = F) %>% mutate(Estado = "Paraná")Pernambuco <- read.csv2("https://leismunicipais.com.br/coronavirus?estado=PE", encoding = 'UTF-8', sep=",", stringsAsFactors = F) %>% mutate(Estado = "Pernambuco")Piauí <- read.csv2("https://leismunicipais.com.br/coronavirus?estado=PI", encoding = 'UTF-8', sep=",", stringsAsFactors = F) %>% mutate(Estado = "Piauí")Rio_de_Janeiro <- read.csv2("https://leismunicipais.com.br/coronavirus?estado=RJ", encoding = 'UTF-8', sep=",", stringsAsFactors = F) %>% mutate(Estado = "Rio de Janeiro")Rio_Grande_do_Norte <- read.csv2("https://leismunicipais.com.br/coronavirus?estado=RN", encoding = 'UTF-8', sep=",", stringsAsFactors = F) %>% mutate(Estado = "Rio Grande do Norte")Rio_Grande_do_Sul <- read.csv2("https://leismunicipais.com.br/coronavirus?estado=RS", encoding = 'UTF-8', sep=",", stringsAsFactors = F) %>% mutate(Estado = "Rio Grande do Sul")Rondônia <- read.csv2("https://leismunicipais.com.br/coronavirus?estado=RO", encoding = 'UTF-8', sep=",", stringsAsFactors = F) %>% mutate(Estado = "Rondônia")Roraima <- read.csv2("https://leismunicipais.com.br/coronavirus?estado=RR", encoding = 'UTF-8', sep=",", stringsAsFactors = F) %>% mutate(Estado = "Roraima")Santa_Catarina <- read.csv2("https://leismunicipais.com.br/coronavirus?estado=SC", encoding = 'UTF-8', sep=",", stringsAsFactors = F) %>% mutate(Estado = "Santa Catarina")São_Paulo <- read.csv2("https://leismunicipais.com.br/coronavirus?estado=SP", encoding = 'UTF-8', sep=",", stringsAsFactors = F) %>% mutate(Estado = "São Paulo")Sergipe <- read.csv2("https://leismunicipais.com.br/coronavirus?estado=SE", encoding = 'UTF-8', sep=",", stringsAsFactors = F) %>% mutate(Estado = "Sergipe")Tocantins <- read.csv2("https://leismunicipais.com.br/coronavirus?estado=TO", encoding = 'UTF-8', sep=",", stringsAsFactors = F) %>% mutate(Estado = "Tocantins")
O que foi feito aqui é bem simples: eu gerei um dataset dos decretos em cada estado, usando como fonte o link do site. Também foi criado uma coluna com o nome do respectivo estado. O que precisa ser feito agora? Ponto para quem disse unir tudo isso.
####################################################
######## Dataset com todos os decretos, por Estado
####################################################DECRETOS_ESTADOS <- list(Acre,Alagoas,Amapá,Amazonas,
Bahia,Ceará,Distrito_Federal,
Espírito_Santo,Goiás,
Maranhão,Mato_Grosso,Mato_Grosso_do_Sul,
Minas_Gerais,Pará,Paraíba,
Paraná, Pernambuco, Piauí,
Rio_de_Janeiro,Rio_Grande_do_Norte,
Rio_Grande_do_Sul,Rondônia,Roraima,
Santa_Catarina,São_Paulo,
Sergipe,Tocantins) %>%
reduce(full_join, by = c("X.U.FEFF.Epigrafe",
"Localidade","Ementa",
"Url","Estado")) %>%
rename(Decretos = "X.U.FEFF.Epigrafe")
E prontinho! Agora temos um banco de dados com todos os estados. Observem que utilizei a função reduce. Ela é do pacote purrr e ajuda na hora de unir todos os bancos, para que não seja necessário unir de dois em dois, com o reduce eu faço a união de todos simultaneamente. A união (ou merge) em si é feita com a função full_join do dplyr, nela eu informo as colunas em comum que serão usadas como base para agregar os dados. Depois eu renomeei o nome de uma coluna para um nome mais agradável (cá entre nós, “X.U.FEFF.Epigrafe” não é um bom nome para uma coluna).
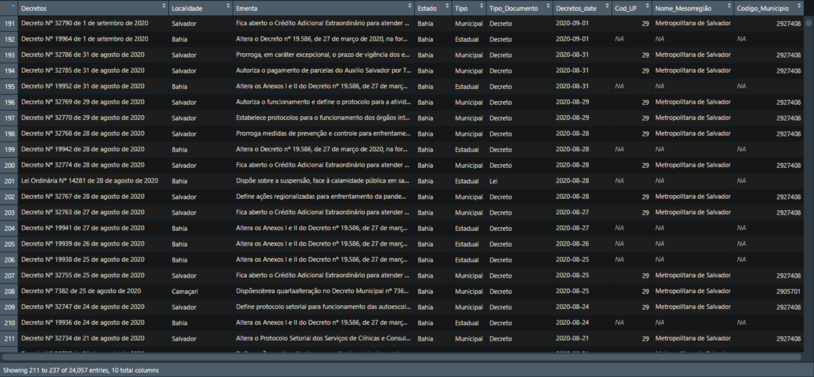
Nossa base de dados tem essa cara por enquanto:

Agora nos precisamos saber se o decreto é municipal ou estadual. Para isso, basta criar uma coluna e aplicar um ifelse usando a ‘localidade’ como informação. Vejam:
### Criando coluna 'Tipo' com informação se o decreto é Estadual ou MunicipalDECRETOS_ESTADOS <- DECRETOS_ESTADOS %>% mutate(Tipo="")DECRETOS_ESTADOS$Tipo <- ifelse(DECRETOS_ESTADOS$Localidade %in% c("Acre","Alagoas","Amapá","Amazonas",
"Bahia","Ceará","Distrito Federal",
"Espírito Santo","Goiás","Maranhão",
"Mato Grosso","Mato Grosso do Sul",
"Minas Gerais","Pará","Paraíba","Paraná",
"Pernambuco","Piauí","Rio de Janeiro",
"Rio Grande do Norte","Rio Grande do Sul",
"Rondônia","Roraima","Santa Catarina",
"São Paulo","Sergipe","Tocantins"), "Estadual", "Municipal")
Agora é necessário incluir os decretos federais. É legal ter um pouco de noção em webscrapping e html. Vamos ver.
Incluindo os Decretos Federais
O site do Governo Federal para obter as informações sobre a legislação sobre o COVID-19 é esse. Se você acessar o site vai notar que ele tem uma interface bem simples, mas não tem nele uma opção de baixar os dados, por isso, precisamos “raspar” as informações que queremos diretamente da página. O R oferece uma gama de opções para raspar informações de páginas da web, o R Selenium é a mais popular, mas aqui optei por usar o PhantomJs.
Faça o download do PhantomJs acessando a página deles, que é essa aqui. Feito o download e depois de descompactar, coloque o arquivo phantomjs.exe na pasta de trabalho que você definiu (a minha, por exemplo, é “C:\\Users\\pc\\Desktop\\Cidacs\\ETL”), basta olhar o primeiro script, no começo do texto, caso não se recorde.
Certo, com o arquivo na pasta, vamos voltar para o R.
###################################################################
###### Decretos Federais - Capturando página e gerando ela em HTML
###################################################################writeLines("var url = 'http://www.planalto.gov.br/ccivil_03/Portaria/quadro_portaria.htm';
var page = new WebPage();
var fs = require('fs');page.open(url, function (status) {
just_wait();
});function just_wait() {
setTimeout(function() {
fs.write('dec_federal.html', page.content, 'w');
phantom.exit();
}, 2500);
}
", con = "scrape.js")js_scrape <- function(url = "http://www.planalto.gov.br/ccivil_03/Portaria/quadro_portaria.htm",
js_path = "scrape.js",
phantompath = "phantomjs.exe"){
lines <- readLines(js_path)
lines[1] <- paste0("var url ='", url ,"';")
writeLines(lines, js_path)
command = paste(phantompath, js_path, sep = " ")
system(command)
}js_scrape()###################################################################
######### Carregando o HTML convertido
################################################################### lendo o html
html2 <- read_html("dec_federal.html", encoding="UTF-8")# criando formato de tabela com dados do html
html_tabela <- html2 %>% html_nodes("table") %>% html_table(fill = T)fed_covid <- html_tabela[[3]]# Ajustando nome das colunas
fed_covid <- fed_covid %>% rename(Decretos = "X1") %>% rename(Ementa = "X2")# Ajustando dados no dataset (Excesso de espaçamento, etc)
fed_covid$Decretos <- gsub("[\t\n]", "", fed_covid$Decretos)
fed_covid$Ementa <- gsub("[\t\n]", "", fed_covid$Ementa)fed_covid$Decretos <- gsub("\\s+"," ", fed_covid$Decretos)
fed_covid$Ementa <- gsub("\\s+"," ", fed_covid$Ementa)# Criando coluna 'Tipo' e 'Localidade'
fed_covid <- fed_covid %>% mutate(Tipo="Federal") %>% mutate(Localidade="Brasil")
Na primeira parte do código, o PhantomJs pelo R é usado para acessar a página do planalto e gerar um arquivo em html. Usando esse arquivo em html, na segunda parte do código, foi utilizada algumas funções do pacote rvest para pegar as informações em html e transformá-la em uma tabela. Após isso, foi necessário aplicar alguns processos de limpeza e ajuste nos dados: renomear colunas, usar um pouco de conhecimento em regex para retirar espaçamento em excesso e por fim criar uma coluna ‘Tipo’ e ‘Localidade’.
Essa é a cara do nosso dataset de decretos federais:
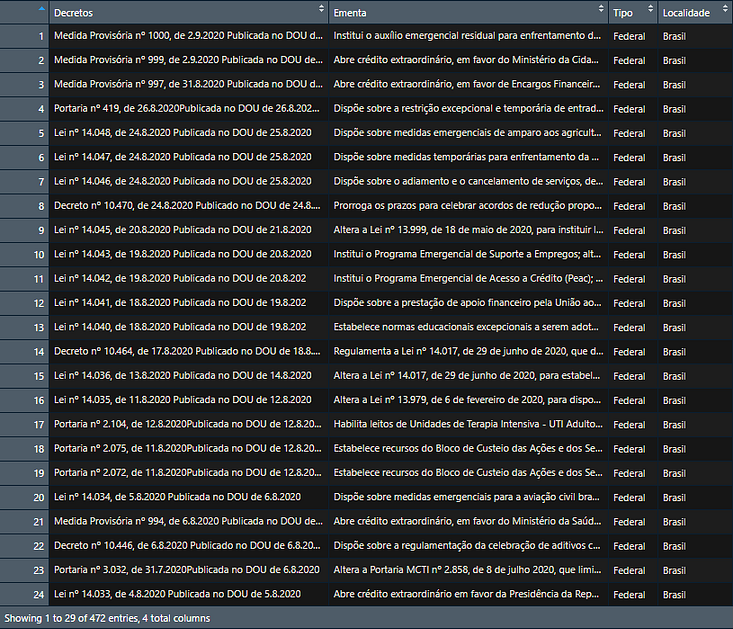
O próximo passo é fazer um merge entre os decretos federais e o restante.
##################################################################
######## Dataset unindo decretos Federais, Estaduais e Municipais
##################################################################Decretos_Covid_Brasil <- full_join(DECRETOS_ESTADOS, fed_covid, by=c("Decretos","Localidade","Ementa","Tipo"))
Criando coluna ‘Tipo do documento’ e limpando os dados
Para saber se o documento é uma Lei, Decreto ou Portaria é preciso usar a função word do pacote stringr. Essa função pega a primeira palavra de cada linha de determinada coluna, no caso, a coluna ‘Decretos’. Também, por questão de limpeza nos dados, é bom deixar o nome do município, na coluna ‘Localidade’, sem nenhum tipo de ‘/’ ou algo que atrapalhe na busca pelo seu nome.
#### Criando coluna 'Tipo do Documento'Decretos_Covid_Brasil$Tipo_Documento <- word(Decretos_Covid_Brasil$Decretos)### Retirando '/' depois do nome do município
Decretos_Covid_Brasil$Localidade <- gsub("\\/.*","",Decretos_Covid_Brasil$Localidade)### Removendo coluna não utilizada
Decretos_Covid_Brasil$Url <- NULL
Inserindo o código dos municípios
Para ajudar na hora de buscar por um determinado município, é sempre melhor usar o código dele do que o nome. Isso porque muitas vezes ocorrem erros de digitação, problemas com acentuação, entre outros. Por isso, é prudente acrescentar uma coluna com o código dos municípios.
Como a coluna que contém o nome dos municípios também tem o nome dos estados, é necessário criar uma condição para que apenas municípios sejam registrados (Para não ter problema, por exemplo, com estados que também tem nome de municípios, como SP ou RJ).
############################################################################## Carregando dataset com códigos dos municípios
####################################################################codigos_igbe <- read.csv2("https://raw.githubusercontent.com/CleitonOERocha/Scripts/master/Decretos%20Covid/codigo_municipios_IBGE.csv",
encoding = "ISO-8859-1", stringsAsFactors = F)### Merge entre códigos e dataset
Decretos_Covid_Brasil <- left_join(Decretos_Covid_Brasil, codigos_igbe, by = c("Localidade","Estado"))### Criando condições para registrar apenas Municípios, e não Estados
Decretos_Covid_Brasil$Codigo_Municipio <- ifelse(Decretos_Covid_Brasil$Tipo == "Municipal",
Decretos_Covid_Brasil$Codigo_Municipio, NA)
Decretos_Covid_Brasil$Nome_Mesorregião <- ifelse(Decretos_Covid_Brasil$Tipo == "Municipal",
Decretos_Covid_Brasil$Nome_Mesorregião, NA)
Decretos_Covid_Brasil$Cod_UF <- ifelse(Decretos_Covid_Brasil$Tipo == "Municipal",
Decretos_Covid_Brasil$Cod_UF, NA)
Inserindo a data do decreto e gerando o banco de dados final
É importante ver a data em que cada decreto foi publicado, tanto para traçar uma linha do tempo, como também para olhar o volume de decretos mês a mês. Para criar a coluna contendo a data é preciso de três pacotes: lubridate, mgsub e gsubfn. Depois de mostrar o script, explico melhor sobre o uso de cada um.
############################################################################# Criando coluna com data dos decretos
####################################################################
### criando lista com nome dos meses em português e seu respectivo número
meses_pt <- c("de janeiro de", "de fevereiro de",
"de março de", "de abril de", "de maio de",
"de junho de","de julho de", "de agosto de",
"de setembro de", "de outubro de",
"de novembro de", "de dezembro de")meses_numb <- c("/01/", "/02/", "/03/", "/04/", "/05/", "/06/", "/07/", "/08/", "/09/", "/10/", "/11/", "/12/")### condição para filtrar data na coluna - criando coluna mês
Decretos_Covid_Brasil$Decretos_date <- ifelse(Decretos_Covid_Brasil$Tipo %in% c("Estadual","Municipal"),
mgsub::mgsub(Decretos_Covid_Brasil$Decretos, meses_pt, meses_numb),
strapplyc(Decretos_Covid_Brasil$Decretos, ", de \\d+.\\d+.\\d+", simplify = TRUE))
### Transformando lista em carácter
Decretos_Covid_Brasil$Decretos_date <- as.character(Decretos_Covid_Brasil$Decretos_date)### Criando condição para extrair datas de acordo com seu padrão
Decretos_Covid_Brasil$Decretos_date <- ifelse(Decretos_Covid_Brasil$Tipo %in% c("Estadual","Municipal"),
strapplyc(Decretos_Covid_Brasil$Decretos_date, "\\d+ /\\d+/ \\d+", simplify = TRUE),
Decretos_Covid_Brasil$Decretos_date)### Convertendo coluna para formato 'Date'
Decretos_Covid_Brasil$Decretos_date <- dmy(Decretos_Covid_Brasil$Decretos_date)
Vamos a explicação:
Os decretos municipais e estaduais tem um padrão: primeiro vem o dia em formato numérico, depois o mês por extenso, seguido pelo ano em formato numérico. Já os decretos federais vem em formato numérico separados por “.”. É preciso, portanto, elaborar duas formas de extrair as datas.
Para os decretos municipais e estaduais: criei duas listas, a primeira com o formato que a data vem no dataset e uma outra com o formato que eu quero que os dados apareceram (/xx/). Ou seja, pretendo aqui fazer uma substituição dos caracteres para um formato de data mais conciso. Para fazer a substituição, foi utilizado a função mgsub do pacote de mesmo nome.
Para os decretos federais: Como não é necessário fazer nenhuma substituição, apenas o recorte da informação, a função strapplyc do pacote gsubfn foi utilizada. Com ela eu consigo recortar a cadeira de caracteres que desejo.
Com essas duas informações em mãos, foi preciso apenas fazer uma condição usando o ifelse. Mas acaba por ai? Nãaaao.
Depois de fazer criar esse if é preciso converter a coluna criada em carácter. Isso porque depois de usar a função strapplyc,o resultado é uma coluna no formato lista. Essa conversão é necessária porque é preciso criar mais uma condição. Explico:
Na primeira condição, apenas houve uma substituição nos valores dos decretos municipais e estaduais. É preciso, como foi feito nos decretos federais, recortar os dados desejados usando a função strapplyc e como não é preciso fazer mais nada com os decretos federais, apenas repete-se o nome da coluna na condição.
Agora que todos os dados estão recortados, contendo apenas a data, é preciso converter essa coluna para o formato correto dela, ou seja, “Date” (que não é de encontro, rsrs). Para isso, bastar usar a função super simples do pacote lubridate, a dmy, que os dados são automaticamente padronizados.
Este é o nosso banco de dados final:

Salvando
Só é preciso agora salvar. Vou salvar do seguinte modo: apenas Salvador, todos da Bahia (estaduais e municipais), Bahia (apenas estaduais), Federais e a base de dados completa, ou seja, para o Brasil todo.
############################################################
############# Dataset com todos os decretos em Salvador
############################################################DECRETOS_SALVADOR <- Decretos_Covid_Brasil %>% filter(Localidade == "Salvador")####################################################################### Dataset com todos os decretos na Bahia - Apenas Estaduais e Estaduais/Municipais ######################################################DECRETOS_BAHIA_ESTADUAL <- Decretos_Covid_Brasil %>% filter(Localidade == "Bahia") %>%
select(Localidade, Decretos, Ementa, Tipo, Tipo_Documento) # Decretos EstaduaisDECRETOS_BAHIA_TODOS <- Decretos_Covid_Brasil %>% filter(Estado == "Bahia") # Decretos do Estado e Municipios#############################################
######## Dataset com decretos Federais
#############################################DECRETOS_FEDERAIS <- Decretos_Covid_Brasil %>% filter(Localidade == "Brasil") %>% select(Localidade, Decretos, Ementa, Tipo, Tipo_Documento)###########################################################
########## Salvando em CSV
###########################################################write.csv2(DECRETOS_SALVADOR,"Decretos_em_Salvador.csv", row.names = F) # SSA
write.csv2(DECRETOS_BAHIA_ESTADUAL,"DecretosEstaduais_na_Bahia.csv", row.names = F) # BA Estadual
write.csv2(DECRETOS_BAHIA_TODOS,"Decretos_na_Bahia.csv", row.names = F) # Ba Estaduais e Municipais
write.csv2(Decretos_Covid_Brasil,"Decretos_Covid_Brasil.csv", row.names = F) # Todos os decretos no Brasil
write.csv2(DECRETOS_FEDERAIS,"Decretos_Federais.csv", row.names = F) # Federais
Conclusão
O script completo está aqui no meu GitHub. Usem! Porém, levou um tempo considerável para elaborar, solucionar erros e ir aprimorando o script, então, se gostou do conteúdo e ele foi realmente útil, por favor, lembre-se de dar os créditos. Isso ajuda pra caramba ❤.
Aqui estão minhas redes sociais: Instagram, LinkedIn, GitHub.
Bônus
Não poderia encerrar sem construir uns gráficos, hahaha.
library(viridis)
library(dplyr)
library(ggplot2)
library(Cairo)
library(tidyr)
library(ggrepel)# Pasta de trabalho
setwd("C:\\Users\\pc\\Desktop\\Cidacs\\ETL")# Dados
Decretos_Covid_Brasil <- read.csv2("Decretos_Covid_Brasil.csv")Decretos_Covid_Brasil <- Decretos_Covid_Brasil %>% mutate(one=1)
Decretos, por mês:
######################## Gráficos - Decretos por mês ################################# Recortando apenas o mês do decreto
Decretos_Covid_Brasil$mes_dec <- format(as.Date(Decretos_Covid_Brasil$Decretos_date), "%m")# Nome do mês
Decretos_Covid_Brasil$mes_dec <- factor(Decretos_Covid_Brasil$mes_dec, levels = c("01","02","03","04",
"05","06","07","08","09"),
labels = c("Janeiro","Fevereiro","Março","Abril","Maio","Junho","Julho",
"Agosto","Setembro"))# Agrupando
total_mes <- Decretos_Covid_Brasil %>%
group_by(mes_dec) %>%
summarise(total=sum(one)) %>%
drop_na()# gráfico
graph_mes <- ggplot(total_mes, aes(fill = mes_dec, y = total, x =mes_dec)) +
geom_bar(position = "dodge", stat = "identity") +
geom_text(aes(label=total),size = 2.5, position =position_dodge(width=0.9),
vjust=-0.5, color = 'black',fontface='bold') +
theme_classic() +
theme(axis.title.x = element_text(colour = "black"),
axis.title.y = element_text(colour = "black"),
axis.text.y = element_text(face="bold", color="#000000",
size=8),
axis.line = element_line(colour = "black",
size = 1, linetype = "solid"),
axis.text=element_text(size=6, face="bold"),
axis.text.x = element_text(face="bold", color="#000000", size=10),
plot.title = element_text(colour = "black", size = 17, hjust=0.5),
legend.position = "none") +
labs(x = "", y="", caption = "Fonte: https://leismunicipais.com.br/\nDados coletados em 08/09/2020",
title = "Total de decretos no Brasil, por mês") +
scale_fill_viridis(discrete=TRUE,option = "B") +
scale_y_discrete(limits=factor(0:6000), breaks = c(0,1000,2000,3000,4000,5000,6000), name = "")# Salvando em PNG
ggsave(plot = graph_mes, "graph_mes.png",
width = 10, height = 5, dpi = 120, units = "in",type = "cairo")

Por ato normativo:
######################## Tipo de ato normativo #################### Agrupando
total_doc <- Decretos_Covid_Brasil %>%
group_by(Tipo_Documento) %>%
summarise(total=sum(one)) %>%
drop_na()# Classificando decretos menores que 100 em 'Outros'
total_doc$Tipo_Documento <- ifelse(total_doc$total < 100,"Outros",
total_doc$Tipo_Documento)# reagrupando e calculando porcentagem
total_doc <- total_doc %>%
group_by(Tipo_Documento) %>%
summarise(total=sum(total)) %>%
drop_na() %>%
mutate(percent = total/sum(total)*100)# criando coluna com a posicao da legenda
total_doc <- total_doc %>% arrange(desc(Tipo_Documento)) %>%
mutate(yposicao_legenda = cumsum(percent)- 0.5*percent)# gráfico
ato_graph <- ggplot(total_doc,aes(x= "", y= percent, fill=Tipo_Documento)) +
geom_bar(width=1, stat = "identity") +
coord_polar("y", start=0) +
geom_label_repel(aes(y=yposicao_legenda, label = sprintf("%1.1f%%",percent)), size = 4,
color = 'black',fontface='bold') +
labs(x="",y="",title = "Tipo de ato normativo", fill = "Ato normativo: ",
caption = "Fonte: https://leismunicipais.com.br/\nDados coletados em 08/09/2020") +
theme_minimal() +
theme(legend.position="bottom",
legend.background = element_rect(fill="ghostwhite", size=0.5, linetype="blank"),
axis.text.x = element_text(face="bold",color="#000000", size=12),
legend.text = element_text(size=10, face="bold"),
legend.title = element_text(size = 8, face = "bold"),
plot.title = element_text(colour = "black", size = 12, hjust=0.5, face="bold")) +
scale_fill_manual(values = c("#581845","#900C3F","#C70039","#FF5733","#FFC300"))# Salvando em PNG
ggsave(plot = ato_graph, "ato_graph.png",
width = 10, height = 5, dpi = 120, units = "in",type = "cairo")

O script dos gráficos vocês encontram aqui.
#R #datascience #Rstats
- Categoria(s): Cleiton Rocha Linguagens de programação